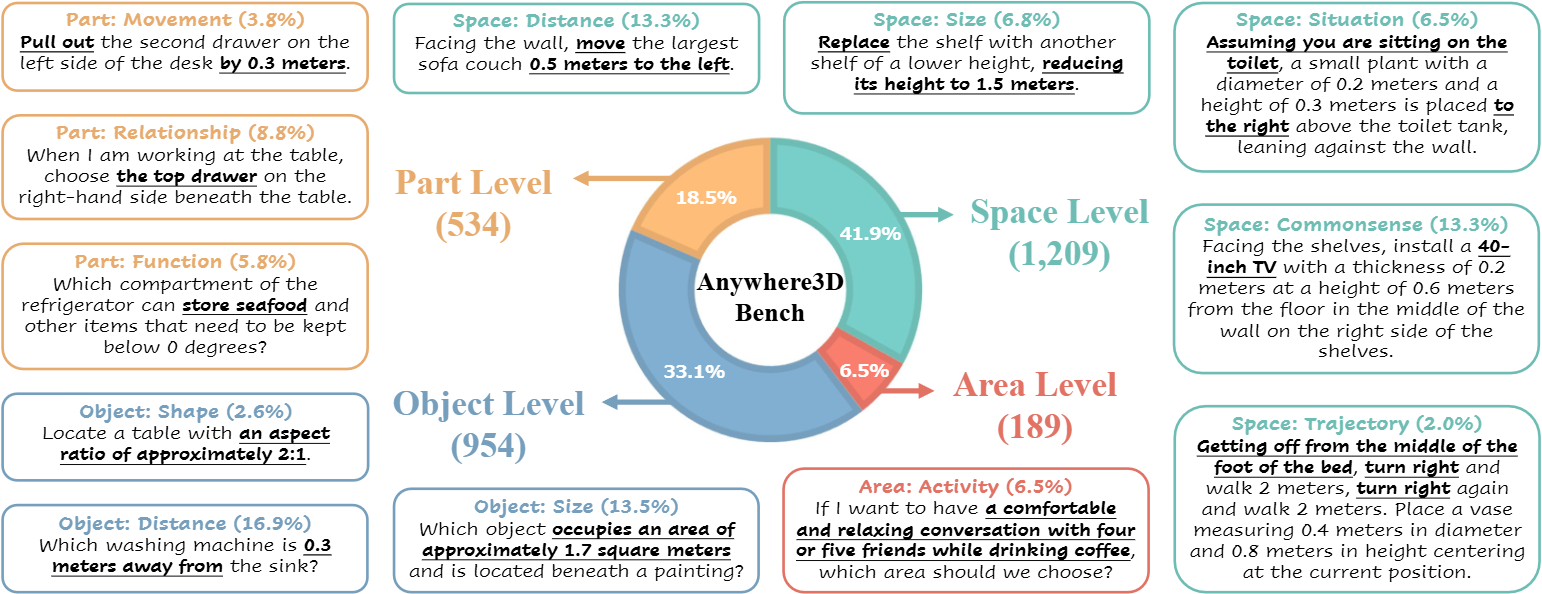
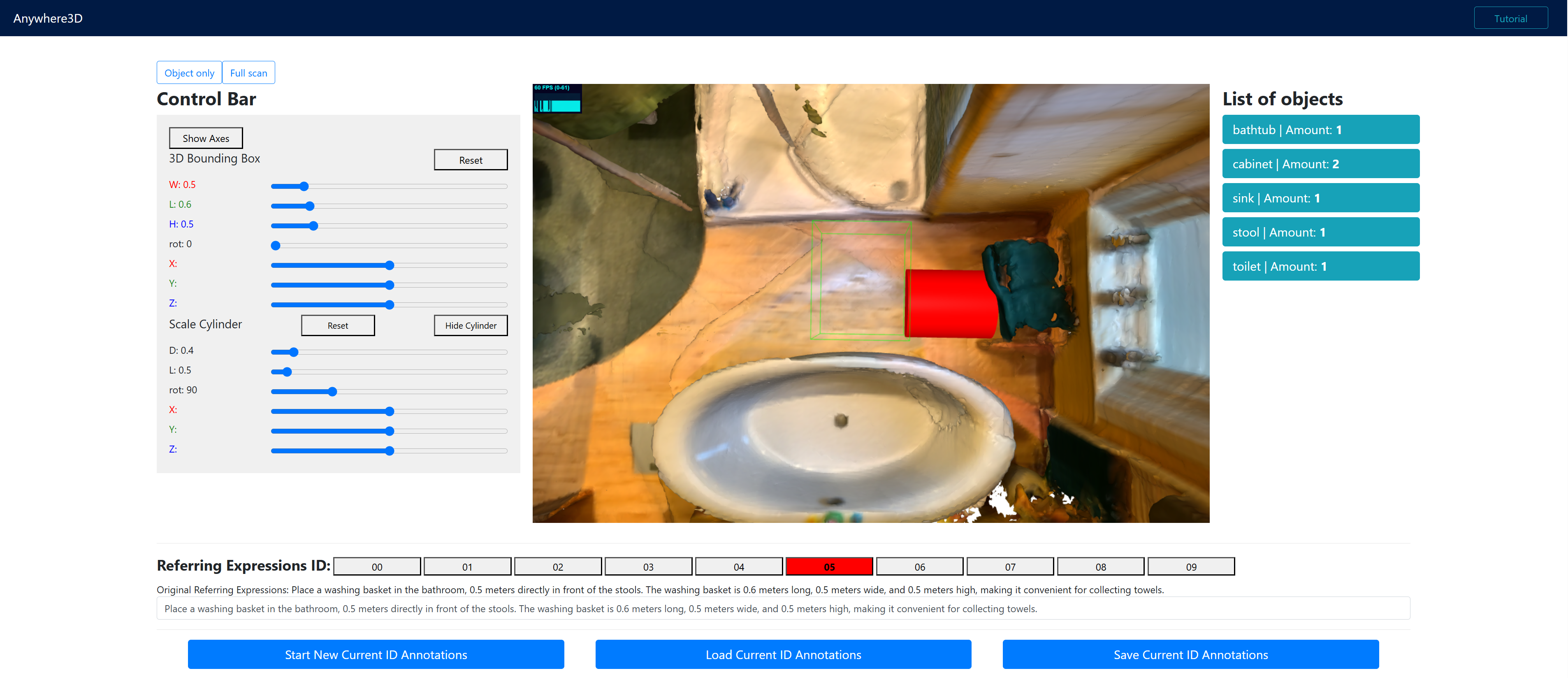
TL;DR We introduce Anywhere3D-Bench, a holistic 3D visual grounding benchmark consisting of 2.8k referring expression-3D bounding box pairs spanning four different grounding levels: human-activity areas, unoccupied space beyond objects, objects in the scene, and fine-grained object parts.

Abstract
3D visual grounding has made notable progress in localizing objects within complex 3D scenes. However, grounding referring expressions beyond objects in 3D scenes remains unexplored. In this paper, we introduce Anywhere3D-Bench, a holistic 3D visual grounding benchmark consisting of 2,886 referring expression-3D bounding box pairs spanning four different grounding levels: human-activity areas, unoccupied space beyond objects, objects in the scene, and fine-grained object parts. We assess a range of state-of-the-art 3D visual grounding methods alongside large language models (LLMs) and multimodal LLMs (MLLMs) on Anywhere3D-Bench. Experimental results reveal that space-level and part-level visual grounding pose the greatest challenges: space-level tasks require a more comprehensive spatial reasoning ability, for example, modeling distances and spatial relations within 3D space, while part-level tasks demand fine-grained perception of object composition. Even the best-performing models, Google Gemini-2.5-Pro and OpenAI o3, achieve just around 30% accuracy on space-level tasks and around 40% accuracy on part-level tasks, significantly lower than its performance on area-level and object-level tasks. These findings underscore a critical gap in current models' capacity to understand and reason about 3D scene beyond object-level semantics.